
之前已经将 kernel-pwn的各种方法都大概复现了一遍。这里主要是由于看到一篇文章,讲到了如何编写一个内核模块,以及搭建Kernel的环境。所以这篇文章,打算跟着走一遍
内核题目基础
这里讲一下一般如何出一道内核题目,主要参考自这篇文章。
编译内核
如果需要特定版本的内核,可以直接下载已经编译好的内核,也可以自己下载内核源码,然后自行编译。
编译内核,首先需要安装一些依赖工具,如下命令:
1 | sudo apt-get install git fakeroot build-essential ncurses-dev xz-utils |
1 | sudo apt-get install flex |
下载了内核源码后,解压后,可以执行如下命令,选择配置:
1 | make menuconfig |
解释一下其中的部分配置:
- kernel debugging
- Compile-time checks and complier options -> Compile the kernel with debug info 和 Compile the kernel with frame pointers
- KGDB:kernel debugger
将config文件中,这一项改为如下形式:
1 | CONFIG_SYSTEM_TRUSTED_KEYS="" |
然后可以运行如命令编译内核,生成 bzImage:
1 | make bzImage -j4 |
-j4参数,是用来加快编译的。编译后,可以从 ./arch/x86/boot/中拿到编译的 bzImage,或者从源码根目录拿到 vmlinux。这里二者的区别,主要如下:
- bzImage 是 vmlinux 经过 gzip 压缩后的文件,适用于大内核
- vmlinux 是 未压缩的内核,其是 ELF文件,即编译出来的最原始文件
- vmlinuz是 vmlinux 的压缩文件
- zImage 是 vmlinux 经过 gzip 压缩的文件,适用于小内核
如果make 时错误提示:
1 | make[1]: *** No rule to make target 'debian/certs/benh@debian.org.cert.pem', needed by 'certs/x509_certificate_list'。 停止。 |
解决方法:打开.config文件并注释掉这一行
CONFIG_SYSTEM_TRUSTED_KEYS="debian/certs/benh@debian.org.cert.pem"
直接vim .config,再把上面那行改成:#CONFIG_SYSTEM_TRUSTED_KEYS="debian/certs/benh@debian.org.cert.pem"
如果要下载编译好的镜像,可以使用如下命令:
1 | sudo apt search linux-image- //得到镜像名 |
构建文件系统
busybox中包含了一些常用的命令,使用 busybox可以快速地构建起文件系统
要想自己编译 busybox,可从这里下载源码。
下载完成后,解压进入源码根目录输入 make menuconfig进行配置。可以进入 Setting选上 Build static binary (no shared libs),这样则不会依赖 libc文件。
然后,输入 make install -j4进行编译,busybox编译要比 kernel快很多。
编译完后会生成一个 install的目录,此时编译已经完成。
后续即可进行一些简单的初始化,例如 创建 proc\sys等文件夹,创建 init文件。init文件是系统启动后的默认入口,如下是最简单的例子:
1 | #!/bin/sh |
有了该文件,我们进入 busybox后就会启动一个最简单的 /bin/sh进程.
一般还需要增加其他文件夹,比如 /etc和 /home,以及一些配置文件:
1 | mkdir etc |
这里我们做题会常见,不做过多解释。这里除了是 init,还可以向 /etc/init.d中增加启动脚本 rcS(BalsnCTF的Kernel题就是如此)。
1 | #!/bin/sh |
启动内核
这里讲一下启动内核的 run.sh文件,常见如下所示:
1 | #!/bin/sh |
讲几个以前不知道的命令,--nographic和 console=ttyS0一起使用,启动的界面就变成当前终端。不然会开一个 VNC服务。
-monitor配置用户模式的网络,将监视器重定向到主机设备 /dev/null
在内核中添加 syscall
在内核源码下,添加一个目录 mysyscall,然后创建 Makefile 和 mysyscall.c
1 | mkdir mysyscall |
mysyscall.c如下示例:
1 |
|
然后,编辑 Makefile如下:
1 | obj-y := mysyscall.o //指定编译的模块名 |
然后修改源码根目录下的 Makefile,添加 mysyscall/模块:
1 | core-y += kernel/ certs/ mm/ fs/ ipc/ mysyscall/ |
再编辑 include/linux/syscall.h,在末尾 #endif之前添加 mysyscall函数原型:
1 | /* my syscall */ |
然后再修改 arch/x86/entry/syscalls/syscall_32.tbl和 arch/x86/entry/syscalls/syscall_64.tbl,添加自定义的 系统调用号:
1 | //syscall_32.tbl |
自此,加完成了 syscall的添加,如果后续调用了 666号,就会调用我们自己的函数。
添加完系统调用后,需要再次编译内核,才会生效。
编译内核模块
在内核源码下添加一个目录 mypwn,然后创建 Makefile和 mypwn.c。
1 | mkdir mypwn |
然后编辑 mypwn.c,如下:
1 |
|
编辑 Makefile如下:
1 | obj-m := mypwn.o //指定模块名 |
然后使用 make命令编译即可。最后将生成的 mypwn.ko放入文件系统打包即可。使用如下命令注册模块:
1 | insmod ./mypwn.ko |
内核 内存管理 slub
关于 slub,看到一篇讲得十分通俗易懂的文章,十分推荐。虽然已有珠玉在前,但是为了加深自己的印象,不免做了搬砖工。
slub 结构体
内核管理页面使用了2个算法:伙伴算 和 slub算法。伙伴算法以页为单位管理内存,所以并不满足大多数程序需要。所以 系统常用的是 slub算法,该系统运行于 slub算法,为内核提供小内存管理的功能,如几字节或 几十个字节。
slub把内存分组管理,每个组分别包含 2^3\ 2^4 \ … \ 2^11个字节,在 4k 页大小的默认情况下,还加上两个特殊的组 96B 和 192 B,总共 11组。当如果需要申请更大的内存时,需要直接使用伙伴系统即可。
slub系统首先需要通过 伙伴系统来获得内存,这里类似 Ptmalloc 从 sysmalloc中获得内存。slub的管理结构中,重点包含 4 类数据:
- 首先是
slub数组 名为kmalloc_caches[12],该数组定义如下:
1 | struct kmem_cache kmalloc_caches[PAGE_SHIFT] __cacheline_aligned; |
每个数组元素对应一种大小的内存,可以把一个 kmem_cache结构体看作是一个特定大小内存的管理链表,按照上述大小分布 总共有 12组。
- 然后是
kmem_cache[12]数组中 每一个kmem_cache结构体,其中有两个重点数据结构kmem_cache_node和kmem_cache_cpu。 kmem_cache_cpu的数据结构如下,其中freelist链表保存了下一快 空闲的内存地址(这里称为object结构体),page指向伙伴系统分配给kmem_cache的一整页连续内存。当申请空闲内存时,会先从kmem_cache_cpu中分配。
1 | kmem_cache_cpu: |
kmem_cache_node结构如下,其中partial也指向一些内存页,如果kmem_cache_cpu中没有满足的空闲内存,那么系统将会从kmem_cache_node中寻找
1 | kmem_cache_node: |
object是指的位于 内存页中的一块空闲内存,该结构如下。物理页是按照 对象object大小组织成单向链表,对象大小由objsize指定;void指向的是下一个空闲的object的首地址,该指针的位置是每个object的起始地址 +offset。这样object对象即可链接为单链表结构。
1 | objsize |
我们可以使用 /proc/slabinfo或 slabtop工具来查看 slab的分配状态
1 | slabinfo - version: 2.1 |
这个文件会显示目前所有的 kmem_cache,第一列是每个 mem_cache的名字,以第一个 nf_conntrack为例说明:
- active_objs:目前使用中的object数量,一共分配出了 408个 objects
- num_objs:总共能够分配的object数量,这里最大是 408
- objsize:每个object的大小,这里为320bytes
- objperslab:每个slab可以有多少个object,这里是51个
- pagesperslab:每个slab对应几个page,这里是4个
slub 分配过程
内核向 slub申请内存块 object时,slub整体流程如下所示。
申请内存
第一次申请
第一次向 slub申请时,此时 kmem_cache_cpu中 和 kmem_cache_node中没有任何可用的 slab可以使用。因此 slub将会向 伙伴系统 申请 空闲的内存页,并把这些页面分为很多个 object。然后取出其中的一个 object,将其标识为 已使用,返回给用户,其余的 object标志位空闲并放入 kmem_cache_cpu中保存。kmem_cache_cpu中的 freelist即保留了下一个空闲 object的地址。
继续申请
当我们继续申请时,此时 kmem_cache_cpu中仍然有空闲对象,所以 继续从 freelist中取出 返回给用户即可。
kmem_cache_cpu无空闲内存
当申请了多次后,此时 kmem_cache_cpu中已经没有 空闲对象,所以会转而向kmem_cache_node申请。如果 kmem_cache_node的 partial中有空闲的 object,所以从 kmem_cache_node的 partial变量中获取有空闲 object的 slub,并返回给用户。
然后kmem_cache_cpu中已经都被占用的 页面都放入 kmem_cache_cpu中,kmem_cache_node中有两个双链表,partial和 full分别盛放不满的页面和全满的页面,kmem_cache_node就是从 partial中挑出slab返回。
kmem_cache_node无空闲内存
当继续申请后,kmem_cache_node中也没有空闲对象后,就只能向内存管理器(伙伴系统)申请 页面,并把该页面初始化,返回第一个空闲对象。
释放内存
向 slub系统释放内存块对象时,如果 kmem_cache_cpu中缓存的页面就是该对象所在页面,则直接把该对象放入空闲链表 freelist即可;如果 kmem_cache_cpu中缓存的页面不是该对象所在页面,然后把该对象释放到该对象所在页面中。释放对象可以分为一下三种情况:
释放前该页面无空闲内存
如果对象在释放前,其所在页面中无空闲内存。那么释放该对象后,该页面就是半满(partial)状态,所以需要把该页面添加到 kmem_cache_node中 partial链表中
释放前该页面是半满
如果释放前该页面是半满状态,即位于 kmem_cache_node的 partial链表中,则直接把该对象放入该页面即可
释放后该页面是全空
如果释放该对象后,该页面是全空状态,则需要将该页面释放掉。
伙伴系统
Linux实现
伙伴系统是用于分配以页为单位的大内存,且分配的内存大小必须都是2的整数次幂,这里的幂次叫 order,例如一页的大小是4K,order为1的块就是 2^1*4K=8k。伙伴系统分配页面主要用到以下函数即数据结构:
__get_free_pages()申请的内存是一整页,一页的大小一般是128K。该函数一般由于大块内存分配,申请的内存一般是连续的物理内存,返回的是虚拟地址(与物理地址相差固定的偏移,可使用 virt_to_phys()来转换),
1 |
|
get_order函数用于从一个整数参数 size(必须是2的幂)中提取 order:
1 |
|
当程序不需要页面时,它可用下列函数之一来释放它们。
1 | void free_page(unsigned long addr); |
可以通过 /proc/buddyinfo来知道每个内存区段上每个order下可获得的数据块数目。
可通过 /proc/pagetypeinfo来查看页面信息。
分配过程
每次分配时都寻找对应order的块。如果没有,就将 order更高的块分裂成2个 order低的块。释放时,如果两个order低的块是分裂出来的,就将他们合并为更高的order的块。
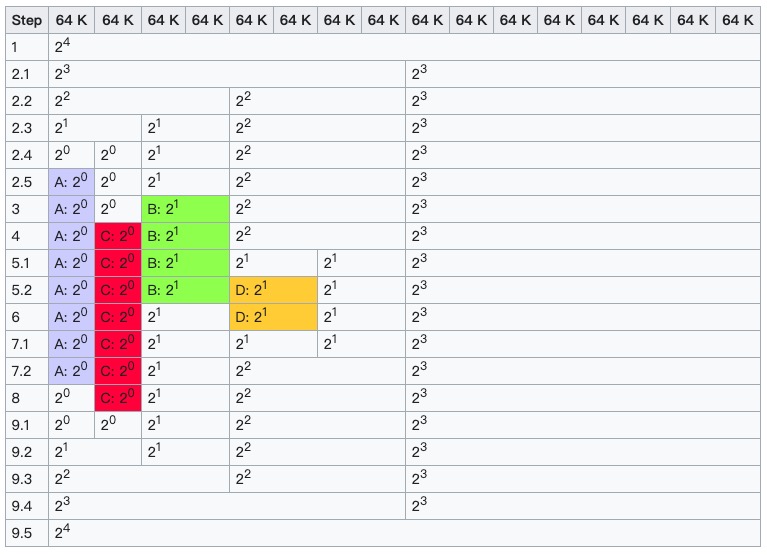
上图示例了分配最小单位是 64K时,初始最大快order=4,依次进行下面的操作:
初始状态
分配块A 34K,order=0
- 没有order=0的块,切分order=4的块为2个order=3的块
- 仍然没有order=0的块,再切分order=3的块
- 仍然没有order=0的块,再切分order=2的块
- 仍然没有order=0的块,再切分order=1的块
- 将order=0的块返回
分配块B 66K,已有 order=1的块,直接分配
分配块C 35K,已有 order=0的块,直接分配
分配块D 67K,无order=1,切分order=2的块,返回
块B释放,order=1空闲
块D释放,因为与6中释放的块,都是由同一个块分裂而来,且都空闲,所以合并为order=2的块
块A释放,order=1空闲
块C释放,依次递归合并
ret2dir
原理分析
linux x86_64内存布局,可以参考此文,其中可以从下图中看到:
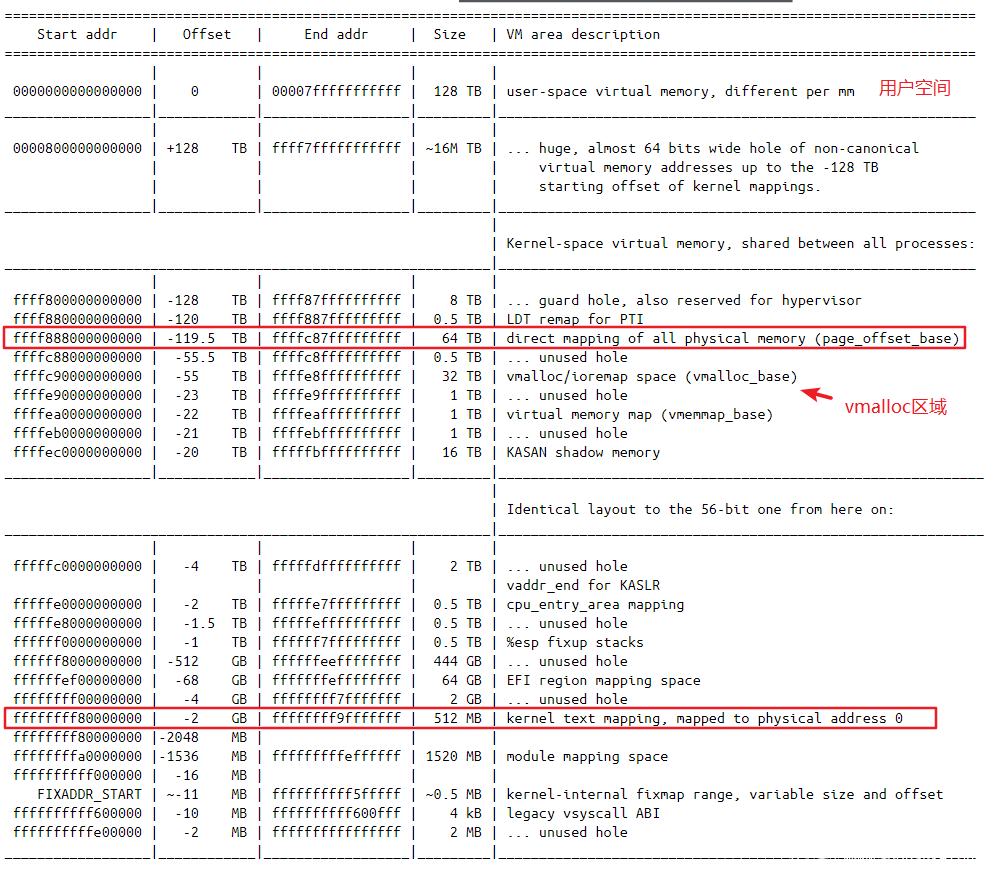
physmap区域直接映射到 0xffff888000000000 - 0xffffc87fffffffff,大小为 64TB。physmap是内核空间中一个大的、连续的虚拟内存空间它映射了部分或所有(取决于具体架构)的物理内存。也即我们的物理内存是会直接映射到该空间内的,而且是所有的物理空间。虚拟空间与物理空间的差别在于一个偏移。
那么,不管是用户虚拟内存空间还是内核虚拟内存空间,其都会映射到物理内存中,而两者都会在 physmap中留下映射。如果我们能够修改 physmap中的对应地址的数据,那么也就能修改用户空间或内核空间的数据。
此外,linux上面已经讲到了两种分配方法,其主要使用 kmalloc和 vmalloc函数:
kmalloc针对字节级做分配,要保证虚拟地址和物理地址都是连续的;
vmalloc请求页的倍数大小的内存,要保证虚拟地址连续,物理地址不连续。
而且 slub分配器是可以在 physmap上做内存分配操作,即 kmalloc(512)是可以分配到 physmap里面。
这里有一篇文章,详细讲述了该原理的测试。
利用分析
ret2dir主要是用来绕过内核 smep,smap的限制。加上 smep,smap保护之后,内核态不能直接执行用户态的代码。但是用户态分配的内存,也会条留在RAM中,这块内存在 physmap中是可以看到的,可以通过 mmap分配大量的内存,这样增大找到用户态内存的概率。早期,physmap是可以直接执行,但现在只能执行ROP。那么总体思路即为在内核地址找到一块用户态可以控制的内存:
mmap大量的内存(rop chains),提高命中率- 泄露出
slab的地址,计算出physmap的地址 - 劫持内核执行流到
physmap上
2018-WCTF-klist
程序分析
1 | __int64 __fastcall add_item(__int64 a1) |
Add函数,可以通过 kmalloc申请一个堆块,并且将堆块的前 0x18当作一个管理结构,如下所示:
1 | 0x0-0x8 flag |
其中 flag用于标记当前堆块的使用次数,size为大小,next指向下一个堆块。并且当将堆块插入 g_list链表时,首先会调用互斥锁,将堆块插入后,再解锁。
1 | __int64 __fastcall select_item(__int64 a1, __int64 a2) |
select用于从 g_list中选择需要的堆块,并放入 file+200处。而且放入时,也会先检查互斥锁,然后再解锁。这里还有一个 get和 put函数,分别如下:
1 | void __fastcall get(volatile signed __int32 *a1) |
get用于将堆块的 flag加1。put用于将堆块的flag减1,并且判断当堆块的 flag为0时,则将该堆块 free掉。这里都是原子操作,不存在竞争。
1 | __int64 __fastcall remove_item(__int64 a1) |
Remove操作,是将选择的堆块,从 g_list链表中移除,并且会对堆块的 flag减1。
1 | unsigned __int64 __fastcall list_head(__int64 a1) |
list_head操作是先调用互斥锁,再从 g_list取出链表头堆块,再调用解锁。输出给用户,然后调用 put函数。
注意:我们查看每一次put操作,发现上面调用 put和 get时,都会调用互斥锁。而这里 在 put时却没有调用互斥锁。也就是存在了一个条件竞争漏洞。我们可以在执行 put函数之前,执行其他函数获得互斥锁,来构造一个条件竞争漏洞。
1 | __int64 __fastcall list_read(__int64 a1, __int64 a2, unsigned __int64 a3) |
然后,read、write都是调用 file+200处的堆块指针。
这里结合 read和 write,就能够构造一个悬垂指针,进而实现任意地址读写。
利用分析
- 构造 UAF
构造一个 fork进程,在子进程中 不断调用 Add和 Select将堆块放入 file+200处,然后再调用 remove将 flag设置为1 。而在父进程中不断调用 list_head。那么就存在这样一种情况。
当父进程的 list_head执行到 put之前时,此时互斥锁已经解锁。那么子进程就可以刚好调用了 一个 Add函数生成了一个新的链表头且执行了 remove此时flag为1,然后父进程执行 put时该新链表头flag减1后,该新堆块就会被释放。然而,此时该新堆块被释放了,却在 file+200处留下了堆块地址,形成了一个悬垂指针。整体流程如下
1 | parent process: child process |
- 任意地址读写
这里的任意地址读写并不是指定地址读写实现,而是通过 UAF漏洞修改 堆块结构中的 size,将其改大。让我们能够读写一个巨大的size。而这里就需要一个能够分配 释放的堆块,并且写入该堆块的函数。这里选择管道 pipe函数,其代码如下:
1 | SYSCALL_DEFINE1(pipe, int __user *, fildes) //--> |
可以看到 pipe函数也是通过 kzalloc实现,而 kzalloc就是加了一个将 kmalloc后的堆块清空。所以也是 kmalloc函数,那么只要size恰当,那么就一定能够将我们上面uaf的 new_chunk_head堆块申请出来,并写上数据。
那么利用pipe函数堆喷,就能够实现对 uaf的 new_chunk_head的size的修改。
- 覆写cred
得到任意地址读写的能力后,提权的方法其实有几种。覆写 cred、修改 vdso、修改prctl、修改 modprobe_path,但是除了 覆写 cred,另外几种都需要知道内核地址。这里无法泄露地址。
那么,直接选择爆破 cred地址,然后将其 覆写为 0,提权。这里选择爆破的标志位是 uid~fsgid在普通权限下都为 1000(0x3e8)。所以只要寻找到这个,就能确定 cred与 new_chunk_head的偏移。
这里我尝试了使用常用的设置 PR_SET_NAME,然后爆破寻找 该字符串地址,以此得到cred地址。但是结果是,爆破了很久在爆破出结果后,就卡住了,无法进行下一步。而调试的时候,竟然发现 子线程会一直循环执行,这点是我目前还没有考虑清楚的问题。
EXP
1 |
|
1 | competition now |
babydriver-ptmx-tty
程序分析
程序已经分析过很多次,由于 babydev_struct是一个全局变量。所以我们每次打开驱动时,都会对该结构体进行操作。而该结构上有一个堆地址,导致我们可以对该堆实现 UAF。
1 | int __fastcall babyopen(inode *inode, file *filp) |
利用分析
之前的方法是利用 fork进程,然后 uaf修改 cred结构体实现。但是最近在学习内存slub算法时,发现线程的 cred结构体的创建是使用 kmem_cache_alloc从 cred_jar链上分配,而这道题我们的堆块分配却是使用 kmalloc,当申请 0xa8时 其只会从kmalloc-192链上分配。这两条链是不会有相同内存块的,那么之前的方法对这道题为什么能成功呢?后面发现这道题的 cred也是从 kmalloc-192上分配的,猜测应该是出题人自己修改了内核源代码,导致这道题可以这样做。
所以,今天学习一下这道题的另一种合理的做法,即劫持 tty-struct,顺便掌握另一种提权方法。
ptmx设备
ptmx设备是 tty设备的一种,当使用 open函数打开时,通过系统调用进入内核,创建新的文件结构体,并执行驱动设备自实现的open函数。其打开创建的文件结构体如下所示:
1 | struct tty_struct { |
这个结构体内含有一个结构体 tty_operations 里面含有大量指针,这简直和 IO_FILE太类似了,如果我们能够修改 tty_struct的 tty_operations,就能劫持函数指针,然后再去触发调用,即能实现劫持程序执行流。
1 | struct tty_operations { |
当调用 open(“/dev/ptmx”, O_RDWR | O_NOCTTY)时,会调用 ptmx_open函数,该函数如下:
1 | //dirvers/tty/pty |
1 | struct tty_struct *tty_init_dev(struct tty_driver *driver, int idx) |
而 kzalloc也是调用 kmalloc来分配堆块。
利用思路如下:
- 构造uaf堆块
首先构造一个 uaf堆块,其大小与 tty_struct大小一致
- 劫持 tty_struct
然后调用 open(“/dev/ptmx”, O_RDWR | O_NOCTTY) 来分配一个 tty_struct,那么很有可能就是分配到 第1步中留下的 uaf堆块
- ROP
这里首先需要通过 uaf漏洞修改 tty_struct中的 tty_operation为我们自己伪造的一个 fake_tty_operation。然后将 fake_tty_operation中构造如下ROP:
1 | fake_tty_operation[7] = mov_rsp_rax_ret; |
由于 fake_tty_operation[7]是 write指针。也就是我们执行如下函数:
1 | write(tty_fd, buf, size); |
会跳转到 fake_tty_operation中的 write指针处执行,而这里的指针被伪造为了 mov_rsp_rax_ret这个 gadget。这是因为,我们发现执行 write指针时 rax刚好为 fake_operations的首地址。那么,执行该 gagdet后,rsp就会跳到 fake_operation[0]处。
然后继续在fake_tty_operation起始的三个地址,布置 gadget,实现了跳转到 ROP处执行的目的。
注意:这里在执行rop时,在执行getshell函数时,可能会报一个段错误,这里可以使用 signal捕捉一个段错误,然后重新执行 system('/bin/sh')来获得 shell。(产生原因已经破案,可以看下面 KPTI部分)
EXP
1 |
|
2019-starctf-hackme
程序分析
1 | __int64 __fastcall hackme_ioctl(__int64 a1, unsigned int a2, __int64 a3) |
程序总体逻辑实现了四个功能:Add可以申请任意大小的堆块,并将堆块地址和size放入 pool中存储;Delete可以根据输入的 id删除pool中的堆块;Write功能 能够指定输入的 size和偏移 off,然后将数据输入到 chunk+off处;Read可以读取 size大小的 chunk+off处的数据。
在 Read和 Write中虽然对 size和off做了检查,即:
1 | size+off < chunk_size |
但是,这里如果我们的 off输入负值,然后 就可以向上越界任意读写了。
利用分析
现在漏洞是一个 向上越界任意读写,那么这道题和 SUCTF的那道题就极其相似。
最开始的想法就是利用向上越界修改一个 空闲内核堆的 fd指针直接指向 modprobe_path来 getshell,但是后面经过调试失败了。虽然能够分配到 modprobe_path,但是修改完之后,执行 system时会报错。猜测应该是分配到 modprobe_path,写入时将其他数据也覆盖了。而这道题在分配堆块时,是会写入数据的,所以直接分配到 modprobe_path有问题(这个问题花了我大概一晚上的时间:(
然后,思考到有一个 pool全局数组,里面存储了 堆地址和 chunk_size。如果能够劫持 pool,将堆地址改为 modprobe_path,那么在利用 write函数,就能实现劫持到 modprobe_path,且仅修改 modprobe_path的值。
- 泄露地址
这道题自己做时,思考的泄露地址很粗暴,就是利用向上越界任意读,去读取前面堆块中的内容,寻找是否有 内核地址 和 驱动地址以及堆地址。最终很幸运,直接0x400的slub向上读 0x800就可以泄露这三个地址。但是这种做法,稍显不靠谱。
后面继续从 P4nda也学到一种方法,即利用 mod_tree地址。如果能够知道 内核地址,就能够知道 mod_tree地址,而mod_tree地址中存储了 驱动地址,如下所示:
1 | pwndbg> x/20xg 0xffffffffbba11000 |
所以,如果能够分配堆块到 mod_tree下面,然后利用向上读,就能泄露驱动地址。
- 劫持 pool
得到 驱动地址之后,就能够得到 pool地址,这里有一个奇怪的点是我目前还未相通的,即 pool地址在调试时其与驱动基址的偏移与 IDA中所看到不一样。目前总结的是,调试时得到的偏移是准确的。
然后利用slub分配,劫持到pool+0xc0处,然后利用 write在 pool+0xc0处写上 modprobe_path和 size。
随后利用 write(0xc),就可以修改 modprobe_path的值。
寻找 gadget,可以先考虑使用 objdump,比 ropper快一点:
1 | objdump -d vmlinux -M intel | grep -E "cr4|pop|ret" |
EXP
从堆块中泄露地址:
1 |
|
从 mod_tree中泄露地址:
1 |
|
覆写 tty_struct,能执行到 ROP,但是会报错,还没解决:
1 |
|
Kernel Pwn状态切换原理及KPTI绕过
system call and return method
int 80
int 80是传统的系统调用,利用中断和异常使用,在执行 int指令时,发生 trap。硬件根据向量号 0x80找到在中断描述符表中的表项,在自动切换到内核栈(tss.ss0:tss.esp0)后根据中断描述符的 segment selector在 GDT/LDT中找到对应的段描述符,从段描述符拿到段的基址,加载到 cs,将 offset加载到 eip。最后硬件将用户态 ss/sp/eflags/cs/ip/error code依次压到内核栈。然后执行 eip的 entry函数,通常在保存一系列寄存器后会 SET_KERNEL_GS设置内核 GS。
返回时,最后会执行 SWAPGS交换内核和用户 GS寄存器,然后执行 iret指令将先前压栈的 ss/sp/eflags/cs/ip弹出,恢复用户态调用时的寄存器上下文。
总结:提权时,如要使用 64位的 iretq指令从内核态返回到用户态,首先要执行 SWAPGS切换 GS,然后执行 iretq指令时的栈布局应该如下:
1 | rsp ---> rip |
syscall
根据 Intel SDM,syscall指令执行时会将当前 rip(syscall的下一条指令地址)存到 rcx,将 rflags保存到 r11中。然后使用 MSR寄存器中的 IA32_FMASK屏蔽 rflags,将 IA32_LSTAR加载到 rip(entry_SYSCALL_6_4),同时将 IA32_STAR[47:32]加载到 cs,IA32_STAR[47:32]+8加载到 ss(在 GDT中,ss就跟在 cs后面)。
在提权时,当使用 sysret指令从内核态中返回,需要先设置 rcx为用户态rip,设置 r11为用户态 rflags,设置 rsp为一个用户态堆栈,并执行 swapgs交换 GS寄存器。
KPTI
早期Linux内核,每当执行用户空间代码时,Linux会在其分页表中保留整个内核内存的映射(内核地址空间和用户地址空间共用一个页全局目录表PGD),并保护其访问。其优点是当应用程序向内核发送系统调用或收到中断时,内核页表始终存在,可避免绝大多数上下文交换相关的开销(TLB刷新、页表交换等)。
KPTI
KPTI(Kernel PageTable Isolation)全称内核页表隔离,通过完全分离用户空间与内核空间页表来解决页表泄露。
KPTI中每个进程有两套页表——内核态页表和用户态页表(两个地址空间)。内核态页表只能在内核态下访问,可创建到内核和用户的映射(用户空间受SMAP和SMEP保护)。用户态页表只包含用户空间,由于涉及到上下文切换,所以在用户态页表中必须包含部分内核地址,用来建立中断入口和出口的映射。
当中断在用户态发生时,就i需要切换 CR3寄存器,从用户态地址空间切换到内核态的地址空间。中断上半部要求切换 CR3寄存器快,KPTI中将内核空间的 PGD和用户空间的PGD连续放置在一个8kb的内存空间中,内核态在低位,用户态在高位)。这段空间必须是 8k对齐,这样将 CR3的切换操作转换为将 CR3值得第13位(由低到高)的置位或清零操作,提高 CR3切换的速度。

所以开启 KPTI后,想提权就比较难,常用的如 ret2user就比较有局限性。
Bypass KPTI
在开启 KPTI内核,提权返回到用户态(iretq/sysret)之前如果不设置 CR3寄存器的值,就会导致进程找不到当前程序的正确页表,引发段错误,程序退出。
那么,就可以在 kernel提权返回用户态的时候绕过 kpti,可以利用内核映像中现有gadget:
1 | mov rdi, cr3 |
来设置 CR3寄存器,并按照 iretq/sysret的需求构造内容,再返回就行。
此外,可以利用 swapgs_restore_regs_and_return_to_us_ermode函数返回:
1 | swapgs_restore_regs_and_return_to_usermode |
ROP时,将程序流程控制到 mov rdi, rsp指令,栈布局如下:
1 | rsp ----> mov_rdi_rsp |
此外,推荐使用修改 modprobe_path提权,无干扰。
TokyoWesterns-gnote
这道题又让我学习到了很多新知识点
程序分析
题目首先就给了源码,从源码中可以直接看出来就两个功能,一个是 write,使用了一个 siwtch case结构,实现了两个功能,一是kmalloc申请堆块,一个是 case 5选择堆块。
1 | ssize_t gnote_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos) |
还有一个功能就是 read,读取堆块中的数据。
1 | ssize_t gnote_read(struct file *filp, char __user *buf, size_t count, loff_t *f_pos) |
然后,虽然给了源码和汇编,看到最后也没发现有什么问题。猜测可能是条件竞争,但是常规的堆块也没有竞争的可能性。TokeyWesterns这题的漏洞出的太隐蔽了,write功能中是通过 switch case实现跳转,在汇编中 switch case是通过 swicth table跳转表实现的,即看如下汇编:
1 | .text:0000000000000019 cmp dword ptr [rbx], 5 ; switch 6 cases |
会先判断 跳转id是否大于最大的跳转 路径 5,如果不大于再使用 ds:jpt_20这个跳转表来获得跳转的地址。这里可以看到这个 id,首先是从 rbx所在地址中的值与5比较,然后将 rbx中的值复制给 eax,通过 eax来跳转。那么存在一种情况,当 [rbx]与 5比较通过后,有另一个进程修改了 rbx的值 将其改位了 一个大于跳转表的值,这里由于 rbx的值是用户态传入的参数,所以是能够被用户态所修改的。随后系统将 rbx的值传给 eax,此时 eax大于 5,即可实现 劫持控制流到一个 较大的地址。
也即,这里存在一个 double fetch洞。
利用分析
- 泄露地址
这里泄露地址的方法,感觉在真实漏洞中会用到,即利用 tty_struct中的指针来泄露地址。
可以先打开一个 ptmx,然后 close掉。随后使用 kmalloc申请与 tty_struct大小相同的 slub,这样就能将 tty_struct结构体申请出来。然后利用 read函数读取其中的指针,来泄露地址。
- double-fetch堆喷
上面已经分析了可以利用 double-fetch来实现任意地址跳转。那么这里我们跳转到哪个地址呢,跳转后又该怎么执行呢?
这里我们首先选择的是用户态空间,因为这里只有用户态空间的内容是我们可控的,且未开启 smap内核可以访问用户态数据。我们可以考虑在用户态通过堆喷布置大量的 gadget,使得内核态跳转时一定能落到 gadget中。那么这里用户态空间选择什么地址呢?
这里首先分析 上面 swicth_table是怎么跳的,这里 jmp_table+(rax*8),当我们的 rax输入为 0x8000200,假设内核基址为 0xffffffffc0000000,则最终访问的地址将会溢出 (0xffffffffc0000000+0x8000200*8 == 0x1000),那么最终内核最终将能够访问到 0x1000。
由于内核模块加载的最低地址是 0xffffffffc0000000,通常是基于这个地址有最多 0x1000000大小的浮动,所以这里我们的堆喷页面大小 肯定要大于 0x1000000,才能保证内核跳转一定能跳到 gadget 。而一般未开启 pie的用户态程序地址空间为 0x400000,如果我们选择低于 0x400000的地址开始堆喷,那么最终肯定会对 用户态程序,动态库等造成覆盖。 所以这里我们最佳的地址是 0x8000000,我们的输入为:
(0xffffffffc0000000+0x9000000*8 == 0x8000000)
那么我们选择 0x8000000地址,并堆喷 0x1000000大小的 gadget。那么这里应该选择何种 gadget呢?
这里的思路是最好确保内核态执行执行了 gadget后,能被我们劫持到位于用户态空间的的 ROP上。这里选用的 gadget是 P4nda学长也曾经提到的 xchg eax, esp,会将 RAX寄存器的 低 4byte切换进 esp寄存器,同时 rsp拓展位的高32位清0,这样就切换到用户态的栈了。
然后我们的 ROP部署在哪个地址呢?这里需要根据 xchg eax, esp这个gadget的地址来计算,通过在 xchg_eax_rsp_r_addr & 0xfffff000处开始分配空间,在 xchg_eax_rsp_r_addr & 0xffffffff处存放内核 ROP链,就可以通过 ROP提权。
然后这里 提权,需要注意上文提到的 KPTI保护,可以利用 modprobe_path来绕过。
EXP
踩着 bsauce大佬的轮子写了一个,但是现在能进入 shell,但是我还是不能提权成功。感觉是执行成功之后并不能执行 system函数,导致虽然用户进程虽然提权成功,但是没有sh。我换成了 execve后,就没问题了。
1 | //$ gcc -O3 -pthread -static -g -masm=intel ./exp.c -o exp |
最终还是得依靠万能的 modprobe_path:
1 | //$ gcc -O3 -pthread -static -g -masm=intel ./exp.c -o exp |
参考
Linux Kernel Heap 101 —— Buddy & Slab


- 本文作者: A1ex
- 本文链接: http://yoursite.com/2021/03/23/Kernel再入门/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!