
学习一下 ret to dl_resolve 原理,虽然该方法有现成的工具可以使用。但是自己还是可以去学习一下原理,随便学习一下 Linux 下 ELF结构。
Linux ELF文件
ELF 文件,是在Linux 中的目标文件,有以下三种类型:
- 可重定位文件,包含由编译器生成的代码以及数据。链接器会将它与其目标文件连接起来从而创建可执行文件或者共享目标文件。其后缀一般为
.o - 可执行文件,即可执行程序
- 共享目标文件,包含代码和数据。这种文件称为库文件,一般以
.so结尾。有两种使用场景:- 链接器,会将 库文件 与其他可重定位文件以及共享目标文件,生成另外一个目标文件;
- 动态链接器 将库文件与可执行文件以及其他共享目标组合在一起生成进程镜像。
目标文件 由汇编器和链接器创建,是文本程序的二进制形式。可以直接在处理器上运行。
文件格式
目标文件机会参与程序链接也会参加程序执行。所以,根据过程的不同,目标文件格式提供了其内容的两种并行试图:
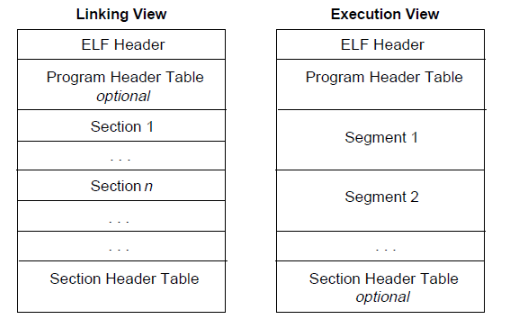
链接形式
文件开始处是 ELF 头部,说明整个文件的组织情况。
如果程序头部表(Program Header Table)存在,会告诉系统如何创建进程。用于生成进程的目标文件必须具有程序头部表,但是重定位文件不需要这个表。
节区部分博阿寒在链接形式中 要使用的大部分信息是:指令、数据、符号表、重定位信息等。
节区头部表(Section Header Table)包含了描述文件节区的信息,每个节区在表中都有一个表项,会给出节区名称、节区大小等信息。用于链接的目标文件必须有节区头部表。
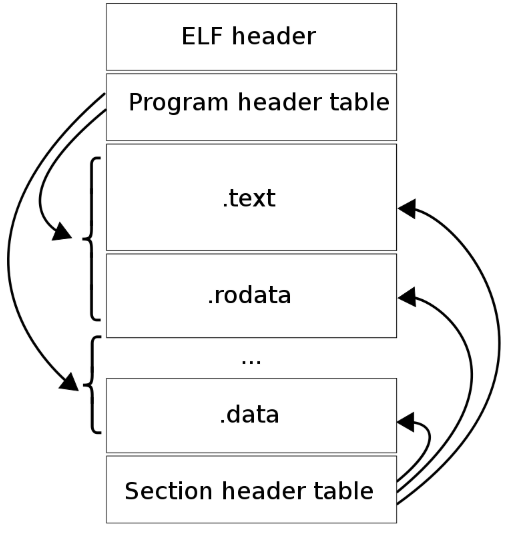
而对于 执行模式,其不同点在于没有 section,而有了多个 segment(来自于 链接模式的 section)。
尽管图中是按照 ELF 头,程序头部表,节区,节区头部表的顺序排列的。但实际上除了 ELF 头部表以外,其它部分都没有严格的的顺序。
数据形式
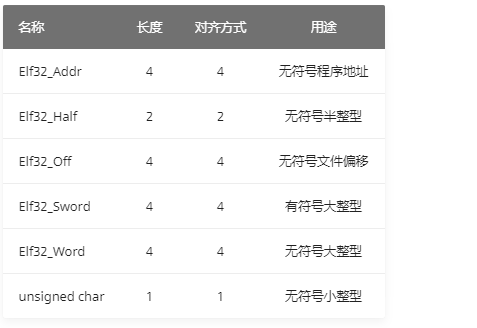
ELF 文件格式支持 8位/32位 体系结构,该格式可以拓展,可以实现目标文件的交叉编译 和平台拓展。
目标文件中的所有数据都遵从 “自然” 大小和对齐规则,如下:
ELF Header
ELF Header 描述了 ELF 文件的概要信息,利用这个数据结构可以索引到 ELF 文件的全部信息,数据结构如下:
1 | #define EI_NIDENT 16 |
Program Header Table
Program Header Table是一个结构体数组,每个元素的类型是 Elf32-Phdr,描述一个段或者其他系统在准备程序执行时所需要的信息。程序的头部只有对于可执行文件和共享文件目标文件有意义。
基地址 - Base Address
程序头部的虚拟地址并不是程序内存镜像中实际的虚拟地址。通常来说,可执行程序都会包含绝对地址的代码。为了使得程序可以正常执行,段必须在相应的虚拟地址处。共享目标通常包含与地址无关的代码,这可以使得共享目标文件可以被多个进程加载,同时保持程序执行的正确性。尽管系统会为不同的进程选择不同的虚拟地址,但是他仍然保留段的相对地址。因为地址无关代码使用段之间的相对地址来进行寻址,内存中的虚拟地址之间的差必须与文件中的虚拟地址之间的差相匹配,这里的思路和 Windows下的虚拟内存差不多。内存中的任何段的虚拟地址与文件对应的虚拟地址之间的差值对于任何一个可执行文件或共享对象来说是一个单一常量值。这个差值就是基地址,基地址的一个用途就是在动态链接期间重新定位程序。
可执行文件或者共享目标文件的及地址是在执行过程中由以下三个数值计算得到:
- 虚拟内存加载地址
- 最大页面大小
- 程序可加载段的最低虚拟地址
要计算基地址,首先要确定可加载段中 p_vaddr 最小的内存虚拟地址,之后把该内存虚拟地址缩小为与之最近的最大页面的整数倍即是基地址。根据要加载到内存中的文件的类型,内存地址可能与 p_vaddr 相同也可能不同。
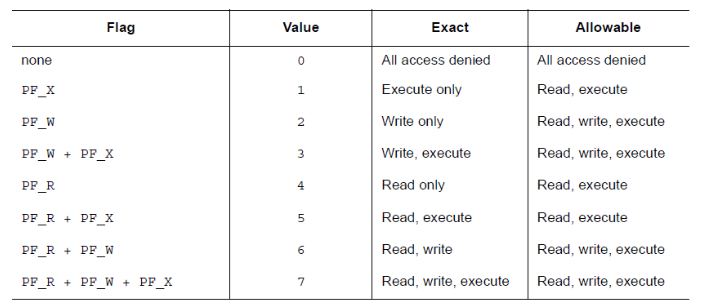
段权限 p_flags
虚拟地址的段页 都具有不同的权限,如下所示:
段内容
一个段可以包含多个节区。
TexT Segment

Data Segment

程序头部的 PT_DYNAMIC 类型的元素指向指向 .dynamic 节。其中,got 表和 plt 表包含与地址无关的代码相关信息。尽管在这里给出的例子中,plt 节出现在代码段,但是对于不同的处理器来说,可能会有所变动。
.bss 节的类型为 SHT_NOBITS,这表明它在 ELF 文件中不占用空间,但是它却占用可执行文件的内存镜像的空间。通常情况下,没有被初始化的数据在段的尾部,因此,p_memsz 才会比 p_filesz 大。
.symtab: Symbol Table
每个目标文件都会有一个符号表,在编译程序时,使用符号表来将函数和变量进行重定位。
目标文件中的符号表包含了一些通用的符号,这部分信息在进行了 strip 操作后就会消失。包括:
- 变量名
- 函数名
符号表数组如下:
1 | typedef struct { |

Relocation Related Sections
在 ELF 文件中,对于每一个需要重定位的 ELF 节都有对应的重定位表,比如说 .text 节如果需要重定位,那么其对应的重定位表为 .rel.text。
例如,当一个程序导入某个函数时,.dynstr就会包含对应函数名称的字符串,.dynsym 中就会包含一个具有相应名称的动态字符串表的符号(Elf_Sym),在 rel.dyn 中就会包含一个指向这个符号的重定位表项。
.rel.plt 包含了需要重定位的函数的信息,使用如下结构。32位使用 Elf32_Rel,64位使用 Elf32_Rela。
1 | typedef struct { |

当程序代码引用一个重定位项的重定位类型或者符号表索引时,这个索引是对表项的 r_info 成员应用 ELF32_R_TYPE 或者 ELF32_R_SYM 的结果。 也就是说 r_info 的高三个字节对应的值表示这个动态符号在. dynsym 符号表中的位置。
1 |
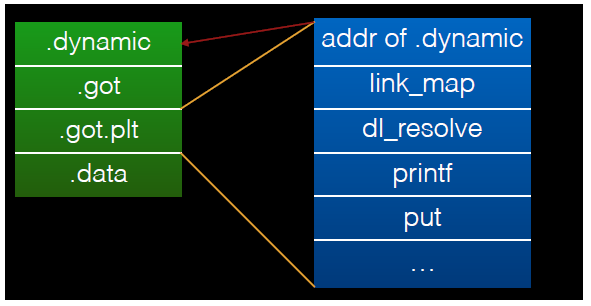
Global Offset Table
GOT表 在ELF 文件中分为两部分:
- .got, 存储全局变量的引用
- .got.plt,存储函数的引用
其相应的值由能够解析的 .rel.plt 段中的重定位的动态链接器来填写
在 Linux 的实现中,.got.plt 的前三项的具体的含义如下
- GOT[0],.dynamic 的地址。
- GOT[1],指向内部类型为 link_map 的指针,只会在动态装载器中使用,包含了进行符号解析需要的当前 ELF 对象的信息。每个 link_map 都是一条双向链表的一个节点,而这个链表保存了所有加载的 ELF 对象的信息。
- GOT[2],指向动态装载器中 _dl_runtime_resolve 函数的指针。
.got.plt 后面的项则是程序中不同 .so 中函数的引用地址,关系如下:
Procedure Linkage Table
GOT 表用来将位置独立的地址重定向为绝对地址。PLT 表则将位置独立的函数重定向到 绝对地址。主要包括:
- .plt, 与常见导入的函数有关,如 read 等函数
- .plt.got, 与动态链接有关系
Lazy Binding机制
在动态链接下,程序模块之间包含了大量的函数引用,程序开始执行前,对所有函数进行动态链接会消耗大量时间。所以采用延迟绑定机制,其基本思想是函数第一次被用到时才进行绑定(符号查找,重定位等),如不用则不进行绑定。
链接器不能解析执行流转换(比如程序调用),即从一个可执行文件或者共享目标文件到另一个文件。链接器安排程序将控制权交给 过程链接表中的表项。过程链接表存在于共享代码段中,其会使用 GOT表中的数据。动态链接器会 决定目标的绝对地址,并且会修改相应的 GOT 表中的内存镜像。
动态链接器和程序按照如下方式解析过程链接表和全局偏移表的符号引用。
- 当第一次建立程序的内存镜像时,动态链接器将全局偏移表的第二个和第三个项设置为特殊的值,下面的步骤会仔细解释这些数值。
- 如果过程链接表是位置独立的话,那么 GOT 表的地址必须在 ebx 寄存器中。每一个进程镜像中的共享目标文件都有独立的 PLT 表,并且程序只在同一个目标文件将控制流交给 PLT 表项。因此,调用函数负责在调用 PLT 表项之前,将全局偏移表的基地址设置为寄存器中。
- 这里举个例子,假设程序调用了 name1,它将控制权交给了 lable .PLT1。
- 那么,第一条指令将会跳转到全局偏移表中 name1 的地址。初始时,全局偏移表中包含 PLT 中下一条 pushl 指令的地址,并不是 name1 的实际地址。
- 因此,程序将一个重定向偏移(reloc_index)压到栈上。重定位偏移是 32 位的,并且是非负的数值。此外,重定位表项的类型为 R_386_JMP_SLOT,并且它将会说明在之前 jmp 指令中使用的全局偏移表项在 GOT 表中的偏移。重定位表项也包含了一个符号表索引,因此告诉动态链接器什么符号目前正在被引用。在这个例子中,就是 name1 了。
- 在压入重定位偏移后,程序会跳转到 .PLT0,这是过程链接表的第一个表项。pushl 指令将 GOT 表的第二个表项 (got_plus_4 或者 4(%ebx),当前 ELF 对象的信息) 压到栈上,然后给动态链接器一个识别信息。此后,程序会跳转到第三个全局偏移表项 (got_plus_8 或者 8(%ebx),指向动态装载器中_dl_runtime_resolve 函数的指针) 处,这将会将程序流交给动态链接器。
- 当动态链接器接收到控制权后,他将会进行出栈操作,查看重定位表项,找到对应的符号的值,将 name1 的地址存储在全局偏移表项中,然后将控制权交给目的地址。
- 过程链接表执行之后,程序的控制权将会直接交给 name1 函数,而且此后再也不会调用动态链接器来解析这个函数。也就是说,在 .PLT1 处的 jmp 指令将会直接跳转到 name1 处,而不是再次执行 pushl 指令。
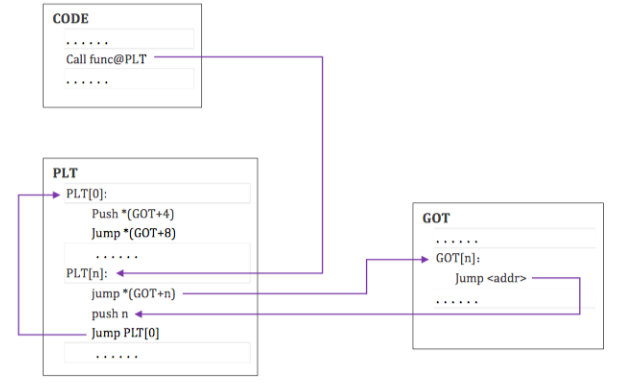
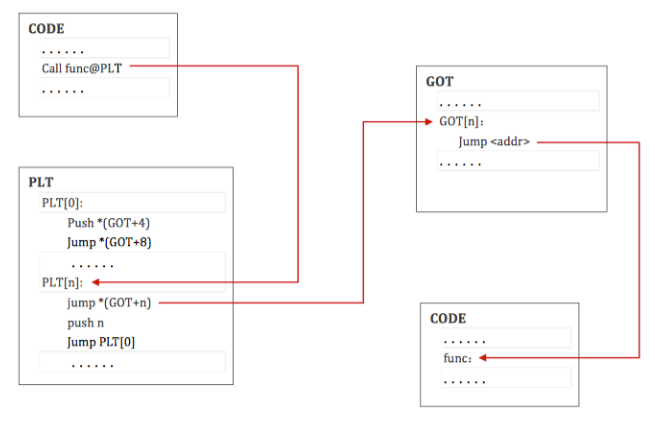
在Linux 的设计中,第一个之后的 PLT 条目进行了如下的函数调用:
1 | _dl_runtime_resolve(link_map_obj, reloc_index) |
这里以 32 位为例,过程如下:
- 根据 reloc_index 计算相应的重定位表项:Elf32_Rel *reloc = JMPREL + index
- 根据得到的重定位表项的 r_info 得到对应的符号在符号表中的索引:(reloc->r_info)>>8
- 继而得到对应的符号:Elf32_Sym *sym = &SYMTAB[((reloc->r_info)>>8)]
- 判断符号的类型是否为 R_386_JMP_SLOT:assert (((reloc->r_info)&0xff) == 0x7 )
- if ((ELFW(ST_VISIBILITY) (sym->st_other), 0) == 0)
- if (sym->st_other) & 3 == 0 )
- 判断该符号是否已经解析过了,如果解析过,就不会再去执行 lookup 操作。
- 得到符号的版本,如果 ndx 为 0 的话,会直接使用 local symbol。
- uint16_t ndx = VERSYM[(reloc->r_info) >> 8]
- r_found_version *version = &l->l_version[ndx]
- 根据 name 来寻找相应函数在库中的地址。
- name = STRTAB + sym->st_name
例子
1.call read函数
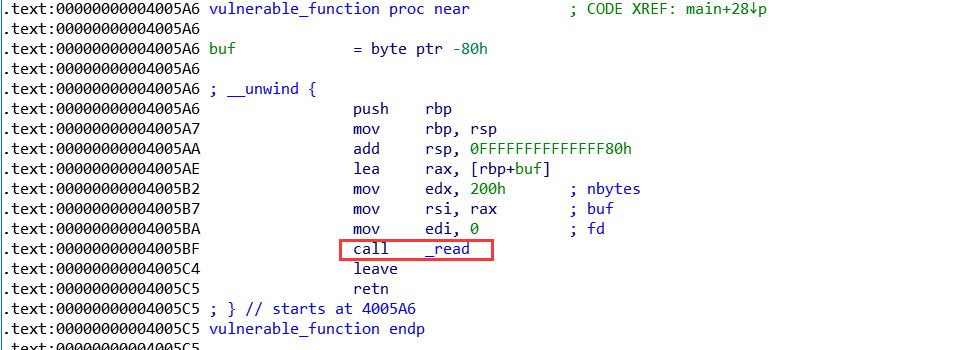
2.会跳到 .plt 表:

3.然后跳到 .got 表项:

4.但是由于初次调用时,.got 还没有保存 read 的真实地址,所以 还会跳到 .plt 表的下一行代码:

5.然后跳到.plt 表的表头,最终去 push 参数,实现将 read 函数的真实地址 保存在 .got.plt 表中

然后就会调用 dl_runtime_resolve 这个函数
_dl_runtime_resolve(*link_map, rel_offset) rel_offset 是 4.中push的值,link_map为 5中push的值。
return-to-dl-resolve调用步骤
- 首先找到 函数的 reloc entry (reloc 入口) rel.plt 结构体 offset 和 info。 push EFL_offset
Elf32_Rel *reloc = JMPREL + reloc_offset; - 然后计算
.dynsym中对应的节入口地址。Elf32_Sym * sym = &SYMTAB[ ELF32_R_SYM (reloc->r-info) ]; - 接着验证 .rel.plt 中 info 的最后一字节为 7
assert( ELF32_R_TYPE(reloc->r_info) == R_386_JMP_SLOT); - 在通过 info 中的
num = (reloc->r_info) >>8。 找到.dynsym 中寸的对应字符串的偏移 Elf32_Sym[num]->st_name = 0x4c(.dynsym + Elf32_Sym_size(0x10)*num),然后再 .dynstr 表中找到对应的 字符串的位置,然后通过字符串搜索到 函数的真实地址 - 函数地址写入对应 got 表,然后执行函数
1 | // param link_map:链接标识符 |
想要利用这个 漏洞要 充分理解明白这个 机制的运行。
1.程序找到对应的重定位函数。
2.通过 num 找到对应函数的 字符串 从而找到函数的真实地址。
攻击手段
- 修改 .dynstr 字节中的字符串为我们需要的字符串,这样就能在绑定时找到我们想利用的函数
- 修改 REL 类型节的 reloc_offset 也就是偏移,实现绑定 由偏移定位到我们伪造的一个表,从而定位到我们需要的函数。
适用条件
- 未给出 Libc库
- 没有开启 PIE 保护,如果开启了 PIE 保护 则还需要泄露 获取基地址
- 没有开启 FULL RELRO
工具使用
使用 roputils 工具,封装了 对 dl_resolve 方法的利用模块:
1 | dl_resolve_call(self, base, *args) |
将要解析的 Libc 函数名称 Name 以及伪造的 结构体位置 base 传给 dl_resolve_data 函数,将生成的 数据写入 base 处,再调用 dl_resolve_call 函数,参数是伪造的 结构体位置 base 和 libc 函数参数。
2015-XDCTF-PWN200
程序分析
存在一个栈溢出漏洞,且溢出的长度较长,能够满足我们布置一个较长ROP链。
同时,只开启了 NX,也就是地址不随机,这点对于我们很友好。
漏洞利用
如果 该题目 的 Libc 是一个出题者自己编写的 libc,那么我们就需要在 没有 libc 的情况解决它。
尝试使用 ret-to-dl_resolve 方法来解决,总体思路为:
1 | 1.实现栈迁移,能够在一个较大的空闲 可读可写 内存布置 数据,bss段很适合; |
EXP
- 首先我们需要实现栈迁移,这里我们将 EBP 迁移到 bss + 0x800除,该地址大部分为空闲状态。同时,我们根据 ROP调用 plt0 地址和传入 正确的 write函数的 index_offset 来实现 读取我们传入的 /bin/sh 字符串:
1 | from pwn import * |
通过上述操作,我们最终能够成功读取到 /bin/sh 数据
- 然后,我们在栈上 部署自己的 fake_JMPREL Relocation Table。然后通过将 该 fake_JMPREL - rel_plt 地址算 index_offset
1 | from pwn import * |
- 然后,我们伪造 fake_r_info,修改其中的 dyn_symobls 地址。并将 我们伪造的 fake_symbols 部署在 bss 中
1 | from pwn import * |
- 现在需要 伪造 fake_write_symbol 数据中的 dyn_str,使得 能够解析到 我们伪造的 fake_str 数据
1 | from pwn import * |
- 通过上面,其实我们已经完全实现了一个 自己伪造的 write 函数的 动态加载。现在我们只需要将 伪造的函数名称 fake_dyn_str 改为 system,并修改 调用的参数。即可实现 getshell。
1 | from pwn import * |
自此,ret-to-dl_resolve 的整个利用流程,就已经完成。但是也可以直接使用工具实现:
1 | from pwn import * |
2015-hitcon-readable
这道题,是64位下的 dl_resolve 利用。可以看到有栈溢出漏洞,只开启了 NX,符合要求。
程序分析
首先也是修改 rbp 为 bss 地址实现 栈迁移,然后是 修改 ret 地址为 main 地址实现多次 read。
然后是部署 dl_resolve 数据到栈上。
EXP
1 | from pwn import * |
但是,我并没有利用成功。目前还搞不清楚是什么原因,感觉数据我都伪造正确了。这个以后还需要思考,如果有谁知道能够给我解答我也万分感谢。
2015-rctf-shaxian
程序分析
程序实现了多个功能,其中漏洞点在diancai 功能中,发生了一个堆溢出。堆大小为0x28,写入时却能写入0x3c 的数据。并且 gouwuche 堆块中,第36位 是一个 next 指针指向 前一个堆块。
而且程序只开启了 CANNARY 和 NX,没有开启 PIE。
漏洞利用
后续再来


- 本文作者: A1ex
- 本文链接: http://yoursite.com/2020/08/08/ret-to-dl-resolve-学习/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!