
很经典的一道Turbofan优化机制引发漏洞的题目,希望通过这道题目的学习能对Turbofan机制的大概流程有一个基本的了解
题目分析
题目链接:
题目附件主要包含3个文件:
addition-reducer.patch:V8的patch文件nosandbox.pathc:V8沙箱的patch文件- chrome:一个编译好的
chrome文件
环境搭建
这里可以根据给的chrome查到v8的版本,然后获得v8的commit
。然后就是正常的在本地搭建:
1 | git reset --hard e0a58f83255d1dae907e2ba4564ad8928a7dedf4 |
然后是加载patch:
1 | git apply ../../googlectf/google/addition-reducer.patch |
patch分析
这里我们主要关注addition-reducer.patch的代码,这里分段说明每一部分的作用:
1 | diff --git a/BUILD.gn b/BUILD.gn |
首先在compiler中新增了两个文件duplicate-addtion-reducer,compiler文件夹一般是放置编译相关的文件。
1 | diff --git a/src/compiler/pipeline.cc b/src/compiler/pipeline.cc |
接着我们先看对pipeline.cc的修改,这个代码可以知道是Turbofan优化的相关代码。这里可以看到是对Turbofan优化的TypedLoweringPhase阶段的优化做了修改,这里是新增了一个DuplicateAdditionReducer优化。那么可以大概猜测漏洞产生的原因是由于Turbofan优化所导致的。
1 | diff --git a/src/compiler/duplicate-addition-reducer.cc b/src/compiler/duplicate-addition-reducer.cc |
重点关注duplicate-addition-reducer.cc文件,看看是增加了何种优化方法。重点关注DuplicateAdditionReducer::ReduceAddition函数,在这个函数中优化的主要是如下示例代码:
1 | x+1+1 |
在IR图中,表现为左节点是一个变量,右节点和右节点的父节点都是一个常数。然后会将这个代码优化为如下所示:
1 | x+2 |
也即将右节点和其父节点的值相加,然后合并为一个节点。
漏洞分析
那么上述的patch会导致何种问题呢?这里需要首先对Turbofan的相关机制有一定的了解,这里可以参考这篇文章:
Introduction to TurboFan
我这里就不做搬运工,但是大概讲解一下和本题有关的知识:
Turbofan优化阶段
Turbofan优化不是一蹴而就的,而是通过不断累加的优化机制达到最终的优化结果。其使用的根本原理是一种预测性speculative优化,即通过运行过程中的反馈预测该对象在未来执行时的类型、数值范围等,然后根据对象的类型删减不必要的检查、查找等操作,从而使得最终生成的指令更加精简。与C、C++相比,解释型语言的问题就是无法在静态分析编译时就确定一个对象的值,这是JS更加便捷的原因,但是也是导致JS执行效率更慢的原因。所以,一旦能够通过执行实现预测,那么就能显著提升JS的执行性能。
执行时反馈收集、生成是由Iginition负责,这里不做详述。
收集的反馈有一部分将会被Turbofan使用于优化字节码,而Turbofan内部也会通过多个阶段来一步步优化生成最终的汇编指令。这里整个阶段十分复杂庞大,所以这里只说明与本题目有关的优化:
Grapgh Build Phase:该阶段主要是根据Ignition生成的字节码来生成IR初始图,后续的优化都是针对这个IR图进行的优化
Typer Phase:将会遍历整个IR图的每个节点,并为每个节点生成对应的Type
Typed lowering phase:该阶段会根据每个节点的Type,进一步优化部分节点的type和range等
Simpilified lowering phase:该阶段会遍历整个IR图的节点,优化部分无关节点,例如不必要的边界检查、不需要的重复操作。
Typed lowering phase
首先对这个阶段进行一个大概说明,因为我们的patch代码就是修改的这个优化部分。该代码在compiler/pipeline.cc中的TypedLoweringPhase结构下。
我们使用如下测试代码:
1 | function opt1(b){ |
生成的Typer phase阶段的IR图如下:
这时候还没有进入typed lowering阶段。此时,我们主要关注图中的3个部分,第一个部分是两个NumberConstant变量,根据前面的相关文档可以知道Turbofan对于一个Number是使用一个Range来表示的。其代码在compiler/types.cc路径下:
1 | Type Typer::Visitor::TypeNumberConstant(Node* node) { |
注意,这里的Range表示每个value都是 double类型
这两个范围其实x的两个可能的值,这里我称为x1和x2,其Range分别是Range(9007199254740992, 9007199254740992)和Range(9007199254740989, 9007199254740989)。然后经过一次Phi节点后,会将这两个范围进行合并Range(9007199254740989, 9007199254740992)。
在第2部分中,其实就是x+1+1代码中的这个常数1。这里可以看到其Range(1, 1)。
而第3个部分就是我们代码中的x+1+1的两次加操作,可以看到此时还是分成两次SpeculativeNumberAdd操作,其期望的返回值类型是Number,但是每一次的结果Range都会有所不同。第一次Range(9007199254740990, 9007199254740993),第二次Range(9007199254740991, 9007199254740994)。
然后,我们进入Typed lowering阶段,即会触发patch的优化代码,其生成的IR图如下:
在IR图中可以很直观的看到优化带来的改变。
在x+1+1代码中,此时的两次SpeculativeNumberAdd被合并为了一次NumberAdd。而此时的常数也被合并为来Range(2, 2)。
而我们纵观两张图中的最终NumberSubtract操作的Range貌似是没有区别的。但是我们需要处理的节点数量确实是减少了,这就是Turbofan优化的能力。
Simplified lowering
这里还需要重点说明Simpilified lowering阶段,对于部分节点的消除。该代码在compiler/simplified-lowering.cc下,其中可以看到当遍历到各种类型的节点后其会有对应的处理。
这里我们主要关注对于CheckBounds节点的处理,代码在compiler/simplified-lowering.cc的VisitNode函数中:
1 | void VisitNode(Node* node, Truncation truncation, |
这里的处理逻辑是,当遇到CheckBounds节点后,先获取处理的访问的索引index和被访问的内存的length。前面已经提到Number是用Range
范围表示,所以这里会判断是否满足index.min>=0&&index.max<length.min,如果满足则说明这个检查是一直都满足的。那么则说明我们在运行过程中是不再需要加上这个检查,所以会执行DeferReplacement函数将这个CheckBounds节点去除。
注意,这里可以看到进入DeferReplacement()函数有一个检查,lowering->poisoning_level_ == PoisoningMitigationLevel::kDontPoison
而要设置
poisoning_level,需要我们在编译 d8 前设置一个配置参数为:
echo “v8_untrusted_code_mitigations = false” >> out.gn/x64.debug/args.gn
这表现在我们的IR图中则如下所示:
可以看到checkBounds节点已经被去除。此时Sub节点的结果为Range(2, 3)。
漏洞触发
前面其实已经将patch代码所产生的影响做了大概说明,好像这份代码带来的优化并不会导致Range范围上的问题。但是,前面也提到了Range里的Value是一个double类型,而double类型的处理可能会存在精度上的问题。
具体可以参考这篇文章:
V8的浮点数表示如下:
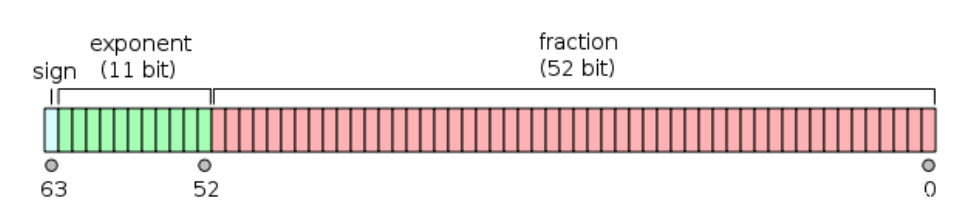
分为符号位S、指数位EXP、有效数位Fraction,分别为1位、11位、52位
浮点数所能表示的最大值就是将所有的有效数位填满, 一共是53位(转化方式如下图),1111……1 , 值为2^53 – 1 = 9007199254740991. 对应的浮点数0x433fffffffffffff
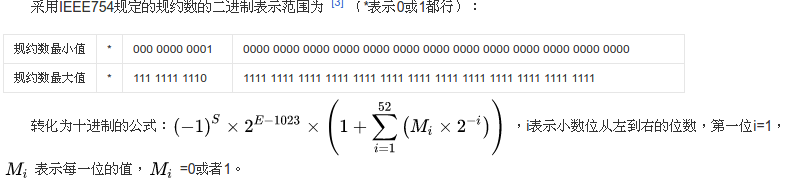
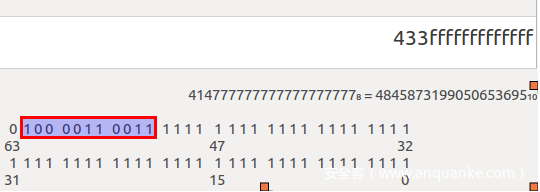
因为9007199254740991=11……1b(53位)=1.111……1b*2^52,指数位Exp=1023+52=1075=10000110011b,符号位S为0。
有效数位只有52位,当超过9007199254740991值时,比如9007199254740992,会在有效数位上加1导致溢出,此时失去精度,其二进制表示为1.0*2^53,由于只有52位,会舍弃最后的一个bit.
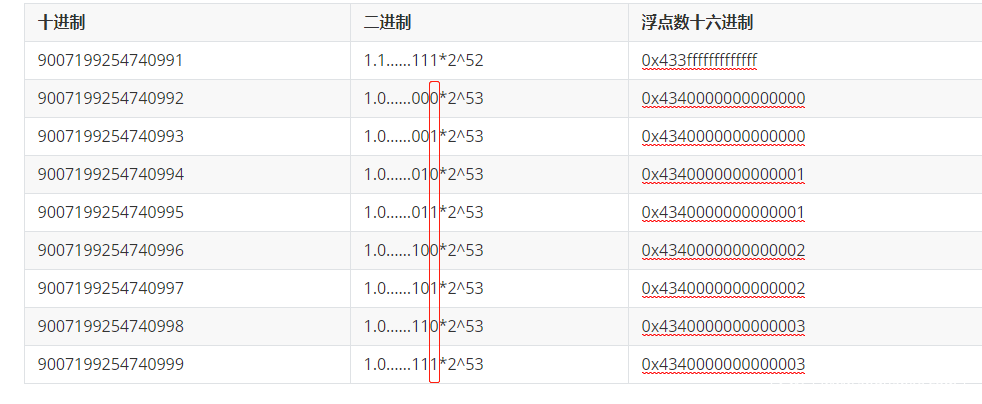
也就是会存在如下结果:
1 | x = Number.MAX_SAFE_INTEGER+1 |
这里当x = Number.MAX_SAFE_INTEGER+1时,x+1+1 != x+2。
那么这里就会导致实际执行和预期检测时的范围不同。
预期检测时Turbofan以为index的Range(2, 3)。
而实际执行时index的Range(2, 5)。所以实际执行时,我们能够访问的范围更大,这里示例代码是能够访问超出2个,但是一定要记住这里理论我们是能够访问超出更多的值,下面会进行示例。
漏洞利用
在前面,我们已经通过POC验证出了一个数组越界OOB。那么很传统的OOB利用思路就是通过OOB去修改一个数组的length为巨大值,然后构造任意地址读写,最后通过wasm去执行shellcode。
前置知识
这里打算对OOB漏洞利用时,经常会用到的几个知识点进行总结。
数组对象布局
JSArray
在POC中,我们经常会使用double array来读取或写入一个浮点数值(也即64位地址)。其内存布局如下:
1 | var arr = [1.1]; |
这里可以看到我们创建的double array,其map是PACKED_DOUBLE_ELEMENTS类型,也即在V8里一个对象的类型是其map决定的,我们可以通过修改一个对象的map来修改其类型,实现类型混淆。
然后可以看到elements属性,其是真正存储浮点数数组的地方,可以看到其map为FixedDoubleArray。
这里还注意到在JSArray和FixedDoubleArray中都有一个length值用来指定数组的大小,在javascript中数组是可以动态扩展的,也就是我们可以随时指定数组的下标并进行读写。那么,究竟是由哪个length值来真正决定一个数组的大小呢?这里可以查看源码objects/js-array-inl.h:
1 | void JSArray::SetContent(Handle<JSArray> array, |
接着,我们看一下当对一个数组进行读取写入时的长度检查的代码,其在ic/ic.cc:
1 | bool IsOutOfBoundsAccess(Handle<Object> receiver, size_t index) { |
可以看到这里获取的length是从receiver中取到,其实是一个JSArray类型,也就是这里与存储数据的FixedDoubleArray类型的长度无关。
所以,如果我们想将一个数组的长度修改大,只需要修改JSArray的length值即可。
此外,如果我们想实现一个任意地址读写,那么只需要修改JSArray.elements的地址为targe_addr-0x10+1,然后使用arr[0]即可读写target_addr的地址。
ArrayBuffer
ArrayBuffer是漏洞利用中比较常见的一个对象,这个对象用于表示通用的、固定长度的原始二进制数据缓冲区。通常我们不能直接操作ArrayBuffer的内容,而是要通过类型数组对象(JSTypedArray)或者DataView对象来操作,它们会将缓冲区中的数据表示为特定的格式,并且通过这些格式来读写缓冲区的内容。而 ArrayBuffer中的缓冲区内存,就是 v8 中 JSArrayBuffer 对象中的 backing_store 。
需要注意的是,ArrayBuffer 自身也有 element。这个 element 和 backing_store 不是同一个东西:element 是一个 JSObject,而 backing_store 只是单单一块堆内存。 因此,单单修改 element 或 backing_store 里的数据都不会影响到另一个位置的数据。
使用如下测试代码:
1 | buffer = new ArrayBuffer(0x400); |
输出如下:
1 | pwndbg> job 0x1f62ad50e291 |
因此,这里我们可以确定JSTypedArray的数据是存储到backing_store地址上的。我们可以通过修改backing_store的地址来实现任意地址写。相关代码如下:
1 | // v8/src/builtins/data-view.tq |
漏洞利用
根据前面的前置知识,然后按照正常的OOB实现数组的越界写,然后通过wasm执行shellcode,方法不过多赘述。
EXP
1 | <script> |
参考文献


- 本文作者: A1ex
- 本文链接: http://yoursite.com/2022/01/14/2018-GoogleCTF-Just-in-Time/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!